Data Cleaning with SQL
You can visit my Github Repository to download the code and data used in this project.
This dataset contains over 50,000 records of data about the housing market in Nashville. It includes owner info, addresses, property value, dates sold, and much more. This dataset had many missing addresses, duplicate records, and dates with bad format. My goal is to import the data to SQL Server and clean it so that it is more useable and looks better.
After importing the Data to SQL Server, we see that the Sale Date Column has a lot of extra numbers. I want to format the column to keep only the date, and get rid of the time.
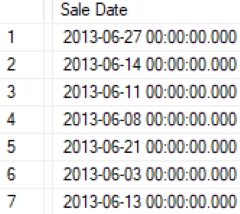
The query below converts the data to a standad date format, and updates the table with the newly formatted data.
--Select Data
Select * From [Nashville Housing Data].[dbo].[Nashville_housing_data]
-- Standardize Date
Alter Table [Nashville_housing_data]
Add SaleDate Date;
Update [Nashville_housing_data]
SET SaleDate = CONVERT(Date, [Sale Date])
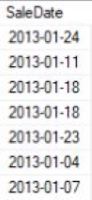
Select [SaleDate]
From [Nashville Housing Data].[dbo].[Nashville_housing_data]This Formatted Date looks a lot cleaner without all the extra info.
There are missing addresses in the Property Address Column. There are also records of addresses with a Parcel ID that correspond to the Parcel ID of the missing values. Since these records share the same Parcel ID, it makes sense that they would also be the correct address. I'll use the addresses from those matching records to fill in the missing data.
-- Property Address Cleaning
-- Populating null values with data found from other values with the same Parcel ID
Select *
From [Nashville Housing Data].[dbo].[Nashville_housing_data]
order by [Parcel ID]
Select a.[Parcel ID], a.[Property Address], b.[Parcel ID], b.[Property Address], ISNULL(a.[Property Address], b.[Property Address])
From [Nashville Housing Data].[dbo].[Nashville_housing_data] a
JOIN [Nashville Housing Data].[dbo].[Nashville_housing_data] b
on a.[Parcel ID] = b.[Parcel ID]
AND a.[F1] <> b.[F1]
where a.[Property Address] is null
Update a
Set [Property Address] = ISNULL(a.[Property Address], b.[Property Address])
From [Nashville Housing Data].[dbo].[Nashville_housing_data] a
JOIN [Nashville Housing Data].[dbo].[Nashville_housing_data] b
on a.[Parcel ID] = b.[Parcel ID]
AND a.[F1] <> b.[F1]
where a.[Property Address] is null
--Removing any remaining null values with no address recorded
Delete from [Nashville Housing Data].[dbo].[Nashville_housing_data]
where [Property Address] is null;Now, I'll check for and remove any duplicate records in the table.
--Removing Duplicate Data
with RowNumCTE AS(
Select *,
ROW_NUMBER() OVER(
Partition by [Parcel ID],
[Property Address],
[Sale Price],
[Sale Date],
[Legal Reference]
Order by
F1
) row_num
From [Nashville Housing Data].[dbo].[Nashville_housing_data]
)
Delete
From RowNumCTE
Where row_num > 1
--Selecting data to check for duplicates
with RowNumCTE AS(
Select *,
ROW_NUMBER() OVER(
Partition by [Parcel ID],
[Property Address],
[Sale Price],
[Sale Date],
[Legal Reference]
Order by
F1
) row_num
From [Nashville Housing Data].[dbo].[Nashville_housing_data]
)
Select *
From RowNumCTE
Where row_num > 1
Order by [Property Address]And finally, removing any unused or irrelevant columns.
--Deleting unused columns
Select *
From [Nashville Housing Data].[dbo].[Nashville_housing_data]
Alter table [Nashville Housing Data].[dbo].[Nashville_housing_data]
drop column [Unnamed: 0], [Sale Date], [Tax District]
This dataset is now clean and uniform and ready for use in later projects.